System Design: Calendar Data Pulling at Scale (Asked in Remitly Interview)
Summary
I recently interviewed with Remitly for a backend role, focusing on system design. The interview covered designing a scalable calendar data pulling system, efficient data storage, and comprehensive monitoring. Despite my detailed approach, I was ultimately rejected without specific feedback.
Full Experience
I recently had an interview with Remitly for a backend role, and this was one of the main system design questions they asked. The interview felt good overall — I designed it using a batch processing approach with a pull scheduler and a pool of workers to handle data ingestion. But unfortunately, I was rejected and didn't get specific feedback.
Here’s the question they asked:
System Design Question
You're building a system to sync appointments from 100k merchants (e.g., salons, doctors) so users can book online.
Merchants expose: GET /appointments?start_date=<>&end_date=<>
Max 1 week per request
Each request takes ~1 sec
To sync 6 months of data = 26 requests/merchant (~26 sec)
You must pull data for all merchants every 10 minutes
Q1: How would you design the data pull system to handle this scale?
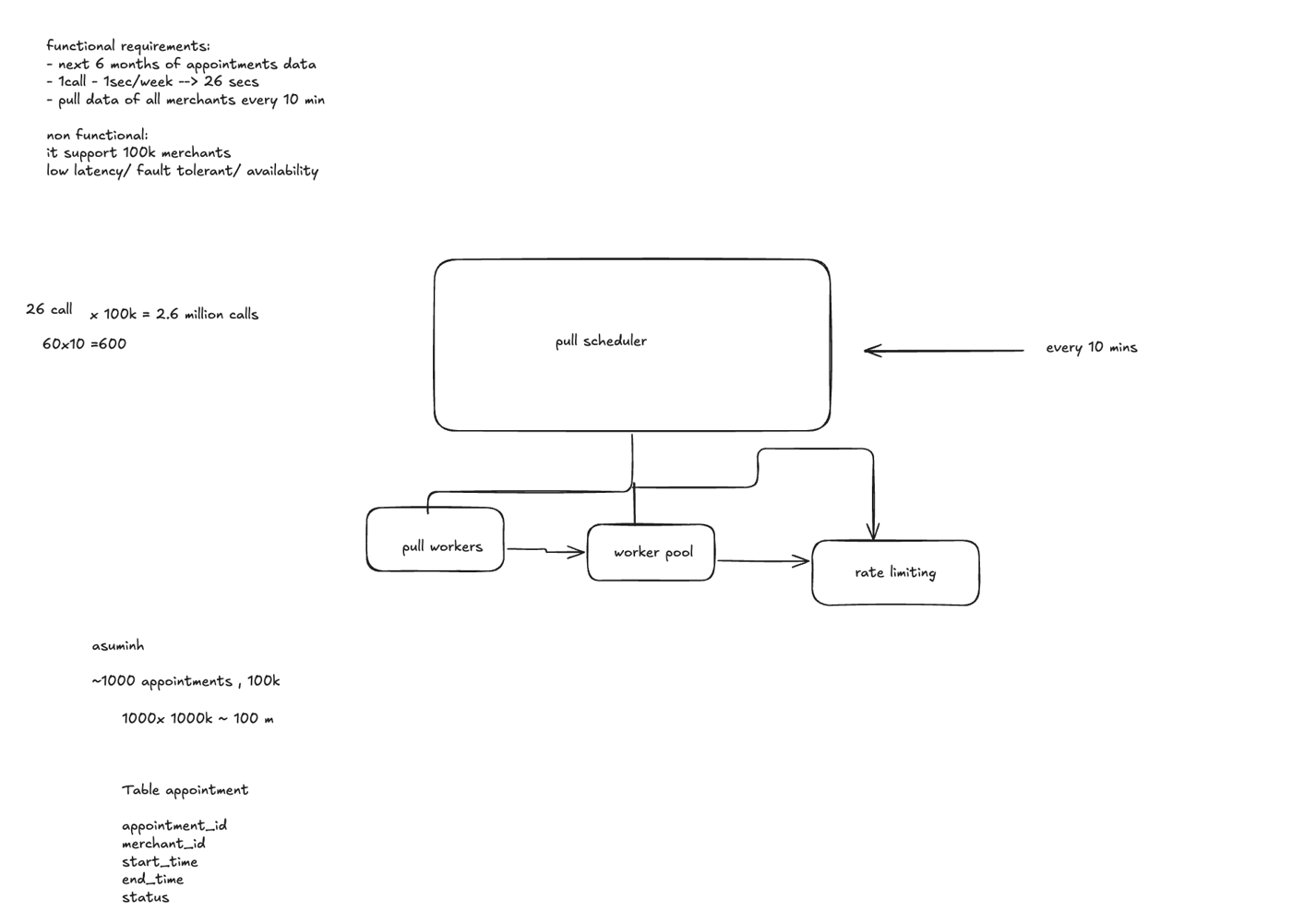
I proposed a batch-based architecture with a pull scheduler that triggers jobs every 10 minutes. A pool of distributed workers handles the pull tasks concurrently. The system was designed to scale horizontally with multiple worker replicas behind a load balancer. I implemented per-merchant rate limiting to avoid overwhelming external APIs and included a retry mechanism with exponential backoff for failed requests. Task queues ensured even distribution and smooth throughput across the system.
Q2: How would you store the data (~1000 appointments/merchant) so that it's efficient to query free slots?
For data storage, each merchant typically has around 1,000 appointments over six months, and since the application’s primary use case is to show available time slots, not just booked ones, the database design focused on efficient querying. I suggested storing appointments with fields like merchant_id, start_time, end_time, and status, indexed by merchant_id and start_time for fast range queries. I also discussed the tradeoffs between using MongoDB vs SQL. MongoDB offers flexibility and fast writes, but querying for free time slots across documents is complex. On the other hand, SQL (e.g., Postgres) offers strong relational capabilities, better for time-based range queries and computing availability using joins and overlaps. I ultimately leaned towards SQL for its querying power and consistency.
Q3: What would you monitor and alert on?
For monitoring, I proposed a Grafana-based observability setup. Key metrics included pull job success/failure rates, API call latency, 429 rate-limited responses, worker CPU/memory usage, task and retry queue depth, and system throughput (e.g., merchants synced per cycle). I also outlined alerts for conditions such as high pull failure rates, slow job execution, queue backlogs, spikes in API errors, and resource saturation.
Interview Questions (3)
System Design: Design a Calendar Data Pulling System for Merchants
You're building a system to sync appointments from 100k merchants (e.g., salons, doctors) so users can book online.
Merchants expose: GET /appointments?start_date=<>&end_date=<>
Max 1 week per request
Each request takes ~1 sec
To sync 6 months of data = 26 requests/merchant (~26 sec)
You must pull data for all merchants every 10 minutes
Q1: How would you design the data pull system to handle this scale?
System Design: Efficient Storage for Calendar Appointments
Q2: How would you store the data (~1000 appointments/merchant) so that it's efficient to query free slots?
System Design: Monitoring and Alerting for a Data Pull System
Q3: What would you monitor and alert on?